原版视频:https://www.youtube.com/watch?v=7xTGNNLPyMI
时至今日,大语言模型已经远远不再会是一个让人感到陌生的词汇,谈到市面上流行的AGI应用,两只手都数不过来,但你是否真的了解AGI呢?当你看到你使用的AI应用给你标出token的价格,看到你点击生成按钮之后激增的token消耗,你是否真的明白什么是token?
也许花一点时间认真地追本溯源,能够帮你更清楚地了解你每天使用的工具,这里强烈推荐安德烈卡帕西的这个视频,链接在文章的开头,三个小时多的讲解抽丝剥茧,通俗易懂,给你一个返璞归真的视角去了解大语言模型的原理。我在这里会用笔记的形式记录这个视频的要点。
大佬介绍
在笔记之前,简单介绍一下安德烈卡帕西这位大佬。
安德烈·卡帕西(Andrej Karpathy)是一位在人工智能领域颇具影响力的斯洛伐克裔加拿大计算机科学家。安德烈先后就读于多伦多大学和斯坦福大学,在师从李飞飞攻读完博士学位后,作为创始团队成员加入 OpenAI 担任研究科学家,负责生成模型的深度学习和深度强化学习。2017年6月加入特斯拉,担任人工智能主管,后领导 Autopilot 以及整个特斯拉自动/辅助驾驶技术项目的研发。2022年7月从特斯拉离职,2023年2月再次加入OpenAI。2024年,他启动了AI教育平台 Eureka Labs。
预训练准备和分词
如果你经常使用GPT的话,也许你会知道GPT的全称是Generative Pre-trained Transformer,这里的 Pre-trained 就是预训练的意思。预训练其实就是给神经网络模型投喂大量的文本内容,让模型学习语言。这个文本内容是来自整个公开网络(排除一些敏感的域名),研究人员会通过爬虫的方式抓取海量的文本,并提取出一些高质量的部分打上对应的标签,用于给模型训练。这里可以参考huggingface建立的一个44TB的数据集(HuggingFace预训练文本数据集),里面详细展示了这些用于预训练的文本集可能长啥样,另外huggingface本身也是一个很有趣的AI社区,大家可以关注一下。

那这些提炼出来的数据集是如何投喂给模型的呢?这里就要提到分词(Tokenization)的概念了。神经网络模型的学习数据可以理解为一个一维符号序列,我们需要把海量的文本转移为这个一维符号序列,并且这个符号集合必须是有限的。很自然地,我们想到采用UTF-8编码将文本转移为只有0和1两个符号组成的序列,但这样这个一维符号太长了,会降低模型学习的效率。我们发现有限符号的集合越大,用这个符号表示文本的序列长度就越短。为了找到一个折衷的方案,我们可以把每8位编码转化为十进制的数字,再根据一些常见的文本组合,去增加一些特定的符号表达,即通过增大一点符号集合去缩短文本序列。以这样的思路出发,我们就可以把一个长文本拆解成用数字表示的小单元,也就是常说的 Token,用于神经网络模型的理解和学习。这里也有一个很棒的网站可以带你去理解分词的过程(Tokenizer),这里可以清楚地看到你输入的文本在不同的模型分词规则下转化成了怎样的Token。
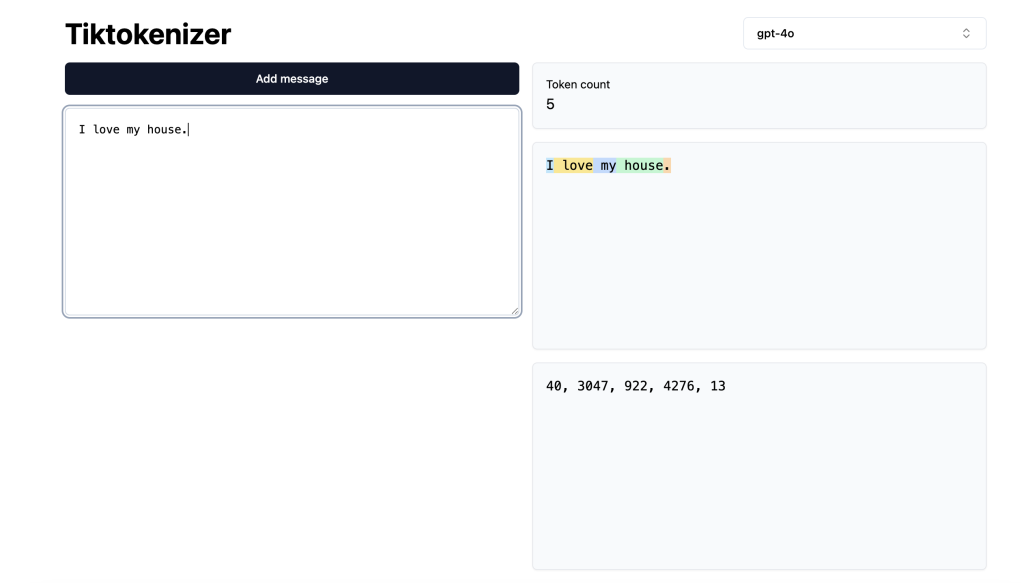
值得一提的是,大模型其实并不会理解这个词具体是什么意思。很多博主在解释token的时候都会用这样一个比喻,说文本转化为Token喂给模型,模型的视角就好比你看到了一大堆emoji。模型所能理解的只有不同Token之间的关联关系和潜在的组合规律,这是大语言模型的一个重要的共识。
Transformer模型预训练
在完成了预训练的文本处理之后,我们就要对模型进行训练了。在训练的过程中,我们要做的就是根据一定token数量的上文,让模型可以准确地推测出下一个token是什么。在实际模型中,这里上文的token数量可能是0到几千(模型的最大上下文长度),安德烈用了四个token来举例,我下面转化成中文举个例子。
我喂给了模型一篇小学生日记,这里有句话是“我想要吃肉”,那么对于模型来说,要做的就是通过前面四个字“我想要吃”对应的token,推测出第五个token对应是“肉”。对于最原始的神经网络模型,通过“我想要吃”来预测下一个字,那所有的结果可能性都是随机的,比如第五个token对应汉字是“人”、“天”、“肉”的概率也许都是1%。然而根据我们文本的内容,我们知道“我想要吃”的下一个字的正确答案是“肉”,模型就会优化一下它内部的参数,使得“肉”的概率高一些,而不那么相关的词的概率就会低一些。假如这个小学生日记里有800个token,那这样的推理优化就会同时发生在这800个token上,直到模型能够根据前文对于文章中每一个位置的token都作出正确的推理预测,这个过程就是模型训练的过程。
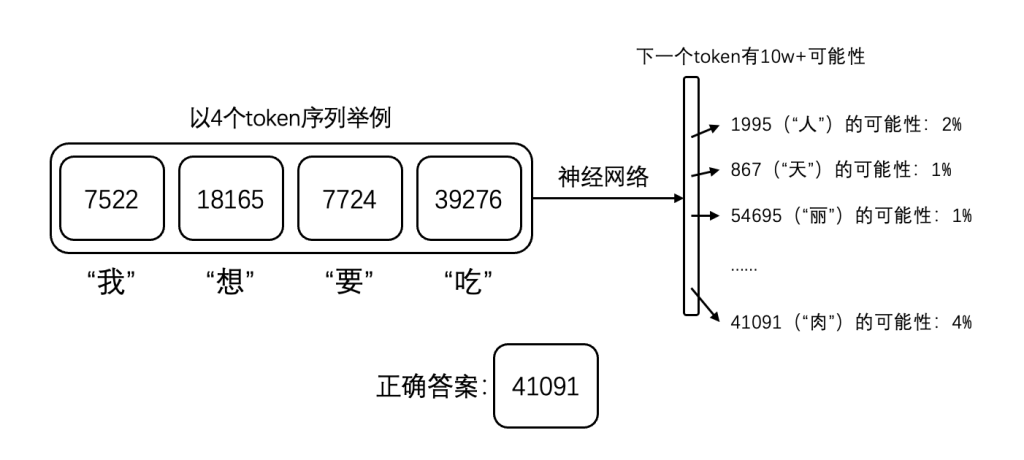
这里只是通过一个例子让人去理解这个模型的输入和输出,以及模型训练的动作其实就是在优化内部参数以获得正确的预测。真实的神经网络模型会涵盖更复杂的数学计算,以及更特殊的结构,这里给出了一个模型可视化的网站(GPT模型可视化网站)用于直观地感受这个模型的参数量级和预测过程。这里提一点Transformer的特点在于它的Attention Matrix,这个大大提升了模型训练的效率和效果,有兴趣可以去搜一下2017年划时代的论文《Attention is all you need》,这里对于Transformer脱离传统循环和卷积神经网络,使用注意力机制构建模型架构做了深入的阐释。当然你如果无法理解的话,也可以像安德烈在视频中讲的那样,简单把神经网络模型当作一个从输入到输出的一个数学函数。
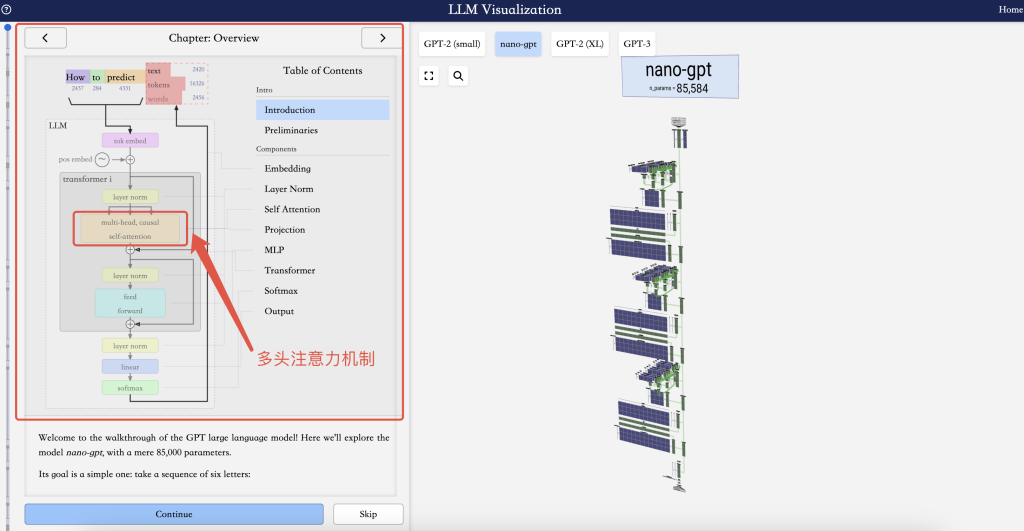
模型的推理生成
当你训练好了一个模型,那这个模型就可以根据上文去进行下一个token的推理。在一些GPT的chatbot里,你可以看到AI的字都是一个一个弹出来的,这里其实每一个token的生成都是一次模型推理的结构。例如模型会根据“我”推测出下一个词是“想”,根据“我想”推测出下一个词是“要”,再根据“我想要”推测出下一个词是“玩”。当然,你可能发现这里生成的“我想要玩”和你训练集中的“我想要吃”有区别,这也是很正常的,因为模型每次推理都是概率生成的结构,每次都会不一样,但一个训练好的模型通常能给出一个合理的推理结果,而不是“我想要餮”或者“我想要髂”这种奇怪的结果。如果你仔细检查你的训练集,可能某处能看到在“玩”之前出现了和”我想要“接近的上文,模型可能也正是在这里的训练中受到了启发而推理出”玩“的结果。
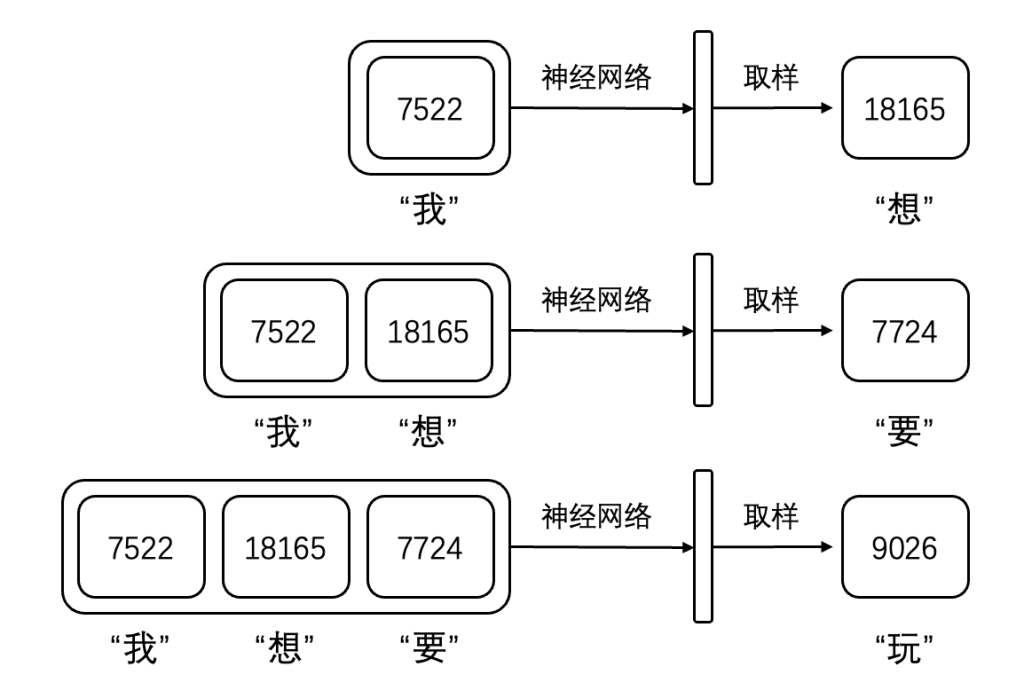
至此,一个基础的神经网络大语言模型的「训练集准备-模型预训练-推理生成」流程已经清晰了。
0 条评论